شاخصهای کلیدی عملکرد (KPI) در مدیریت خدمات فناوری اطلاعات
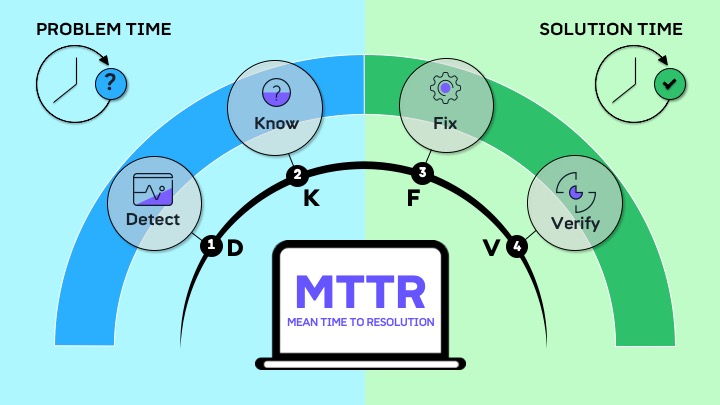
شاید اگر شما هم در فضای مدیریت خدمات فناوری اطلاعات فعالیت کرده باشید عبارتهایی مانند MTTR, MTRS, MTBSI, MTBF و بسیاری موارد دیگر به گوشتان خورده باشد. احتمالا با اینها به عنوان KPI های مهم در رابطه با مدیریت خدمات آشنا شدهاید و شاید حتی در حال پایش و اندازهگیری آنها نیز باشید.
بابک ایزدی مدیرعامل و مشاور ارشد شرکت رایزن سامانه گستر در این نوشته، به زبانی ساده، ضرورت استفاده از شاخصهای اندازهگیری را در کنار پاسخ به سئوالاتی نظیر “چرا باید KPI داشته باشیم؟”، “شاخصهایی مثل MTTR, MTBF و … چه هستند و اندازهگیری آنها برای ما چه کاربردی دارد؟” شرح خواهد داد.
در اغلب مواقع وقتیکه از یک کارشناس و یا تیم فناوری اطلاعات سئوال کنید که مثلا “چرا در حال اندازهگیری MTTR هستید؟” این جواب را خواهید شنید که، “چون مهم است!” بطور معمول اغلب دوستان در حال پایش و اندازهگیری شاخصهای متعددی هستند که برایشان توجیهی جز اهمیت ضمنی (چون شنیدهاند که مهم است) ندارند و در نتیجه انرژی صرف شده جهت این اقدام به تولید ارزش منتهی نخواهد شد.
شاید بهتر باشه که همین اول کار، حداقل این چند شاخصی که نام برده شد را برای دوستانی که ممکن است با اینها برخورد نکرده باشند تشریح کنم و کاربردشان را توضیح بدهم.
اول از همه اینکه تمامی این KPIها ( MTTR, MTRS, MTBSI, MTBF)، از گروه شاخصهایی هستند که در رابطه با موضوع دسترس پذیری سرویس (Service Availability) مورد توجه قرار میگیرند و اصطلاحاً اجزا تشکیل دهنده چرخه عمر یک حادثه یا همان Incident Life-cycle هستند.
- MTTR – Mean Time To Repair که عموما تحت عنوان Serviceability تعریف میشود.
- MTRS – Mean Time to Restore Service که در اغلب مواقع در سایه MTTR محو شده و مورد توجه قرار نمیگیرد.
- MTBF – Mean Time Between Failure که عموما تحت عنوان Availability محاسبه میشود.
- MTBSI – Mean Time Between Service Incidents که از آن تحت عنوان Reliability نام برده میشود.
خب، اگر احتمالا این اسامی را قبلا نشنیده باشید، هنوز هم چیز خاصی دستگیرتون نشده 😉 برای اینکه بخوام اینها را بهتر و اصولی توضیح بدم از اینجا باید شروع کنم که در چارچوب ITIL ما یک عبارتی داریم تحت عنوان Incident یا همون حادثه و یک فرآیندی هم داریم به اسم Incident Management که خب مفهوم حادثه تقریبا از اسمش قابل پیشبینی هستش و عملا به هرگونه وقفه یا کاهش کیفیت برنامه ریزی نشده در ارائه یک سرویس گفته میشه! حالا اون فرآیندی که اسم بردیم قراره چه کار انجام بده؟ فرآیند مدیریت حادثه قرار هست روی این موضوع تمرکز داشته باشه که در کوتاهترین زمان ممکن این وقفه یا کاهش کیفیت پیش اومده رو برطرف کنه و سرویس رو به شرایط عادی برگردونه 🙂 که اینکار بطور معمول توسط تیمهای پشتیبانی یا همون تیمهایی که در ITIL بهشون Service Desk گفته میشه انجام میشه؛
آشنایی با شاخصهای کلیدی در حوزه مدیریت حوادث و دسترسپذیری سرویس/سیستم
این عبارتهایی که بالا به عنوان KPI معرفی کردم در اصل به همین موضوع حادثه مرتبط میشن! چقدر طول میکشه یک حادثه رو برطرف کنیم، چند وقت یکبار حادثه و درنتیجه قطعی داریم و … اما برای توضیح شفاف میتونید شکل پایین رو نگاه کنید.
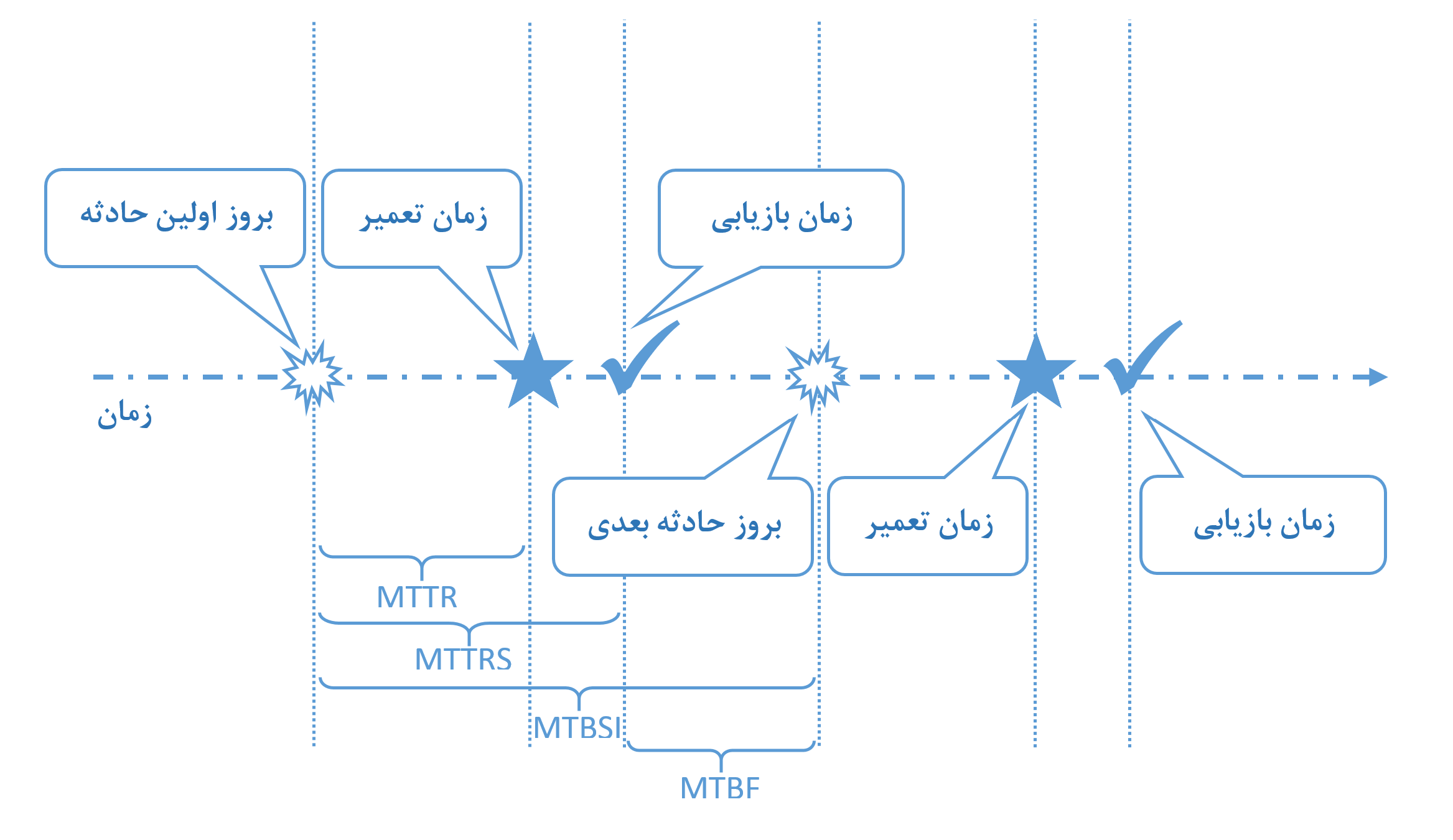
خب، حالا اگر شکل رو دیدن که من یک مقداری روش توضیح بدم. تصور کنید که الان ساعت 10:10 صبح برای یکی از سرویسهاتون مشکل پیش میاد و با قطعی مواجه میشه! خب پس این الان میشه شروع حادثه (Incident)، فرض کنیم که یکساعت طول میکشه تا بفهمید مشکل از کجاست و برطرفش کنید. اسم این یک ساعت رو میزاریم MTTR، اما خب اینکه سرویس بالا بیاد و برگرده به شرایط قبلی ممکنه مثلا نیم ساعت دیگه طول بکشه و اسم این یکساعت و نیم رو که از 10:10 شروع شده رو میزاریم MTRS و الان دیگه بعد از این زمان سرویس در دسترس کاربران هست و اونها دوباره مشغول استفاده از سرویس شدن 🙂
مثال: این سناریو رو در نظر بگیرین که یک مشکلی در کانفیگ سرور پیدا کردین و الان برطرفش کردین، خب الان ظاهر ماجرا اینه که برای اون حادثه Repair اتفاق افتاده و دیگه مشکلی ندارین، اما خب تا سرور رو ریست نکنید و دوباره بالا نیاد سرویس مجددا راه نمیافته، خیلی وقتها همین موضوع ریست شدن و بالا اومدن مجدد سرور و سرویسهای روش زمانبر هستش، پس اینجوری زمان Repair با زمان Restore دو تا چیز جدا میشن، البته مواقع زیادی هم هست که این دوتا با هم یکی میشن و فاصلهای بینشون وجود نداره!
خب این احتمال وجود داره که دوباره ساعت 14:20 یک حادثه دیگه پیش بیاد و بارها و بارها همین چرخه تکرار بشه! این وسط چندساعتی سرویس داشته بدون مشکل کار میکرده که اسمش رو میزاریم MTBF که در اصل به فواصل بدون مشکل ارائه سرویس گفته میشه و دیگه فقط یکی مونده که اونم MTBSI باشه و عملا به فاصله بین 10:10 تا 14:20 میگیم که میشه از بروز این حادثه تا بروز حادثه بعدی!
برای اینکه در رابطه با اهمیت این شاخصها و اندازهگیریشون بخوایم صحبت کنیم، من همیشه سر کلاس یک سئوال ساده میپرسم و مثلا میگم خب الان تصور کنید که شما با مشتری تا 2 ساعت قطعی در طول یک ماه روی سرویسی که ارائه میدین توافق کردین (طبیعتا اینها را توی سند SLA مستند میکنید)! الان به نظرتون آخر ماه مشتری بیشتر خوشحال میشه که کلا یکبار قطعی داشته باشید اما به طول دو ساعت یا اینکه مثلا 2 تا یکساعت باشه یا حتی 4 تا نیم ساعت! طبیعتا میتونید تصور کنید که حتی 120 تا یک دقیقه هم باز میشه همون دو ساعتی که با مشتری توافق کردین 😀
خب حالا اینجا میشه که این شاخصها مطرح میشن و طبیعتا برای سرویسهای مختلف و حتی کاربران مختلف میتونه شرایط کاملا متفاوت باشه، ترجیحمون ممکنه برای خیلی از سیستمها تعداد قطعی کمتر باشه و طول قطعی اهمیت پایینتری داشته باشه اما خب سرویسها و سیستمهایی هم هستند که تحمل وقفههای طولانی رو ندارند و برعکس قبلی تعداد زیادتری رو میتونن در شرایطی که طول وقفه کم باشه تحمل کنن!
اندازهگیری و محاسبه شاخصها
اما نحوه محاسبه این شاخصها هم خیلی مهم هستش و اینهایی که در بخش بالا و توی شکل توضیح دادم مفهوم کلی ماجرا بود. خب الان اگر شما بخواین میزان دسترس پذیری یا همون Availability یک سرویس یا سیستم را در یک بازه زمانی مشخص محاسبه کنید و گزارش بدین کافیه از کل اون بازه زمانی، میزان MTTRS ها رو که یکجورایی نشون دهنده زمان در دسترس نبودن سرویس یا سیستم هست رو کم کنید. یا به نوع دیگه ای بیاین و مجموع MTBF ها رو جمع کنید. اما بطور کلی اگر خیلی فرمولوار بخوام بگم نحوه محاسبه دسترس پذیری میشه:
(کل بازه زمانی منهای زمانهای در دسترس نبودن تقسیم بر کل بازه زمانی) ضربدر 100
مثلا اگر شما در یک ماه 30 روزه 2 ساعت قطعی داشتین خب میشه (((30 *24) – 2) / (30*24)) * 100 که برابر هست با 99.72%
فواصل زمانی بین حوادث و وقفههای سرویس هم که اسم شاخصش رو گذاشتیم MTBSI مولفه خیلی مهمی برای مدیریت هستش که تحت عنوان قابلیت اطمینان یا Reliability میشناسیم و در اصل نشون میده چقدر میتونیم به سیستم مطمئن باشیم و چندوقت یکبار باید توقع مشکل را داشت.
MTTR رو هم که براش عبارت Serviceability رو نوشته بودم خیلی واژه فارسی خوبی نداره اما میتونم براش معادل تعمیرپذیری رو بکار ببرم و این نشون میده که مثلا اصولی که در طراحی و پیادهسازی سیستم رعایت کردین یا حتی مستنداتی که تولید شده چقدر خوب بودن که الان کمک میکنن تا حوادث سرویس در زمان کوتاهی شناسایی و برطرف بشن!
مرور کاربردی
خب حالا که با این تعاریف و مفاهیم آشنا شدین باید اشاره کنم که اصولا این شاخصها رو بصورت میانگین و با استناد به مجموعهای از سوابق در نظر میگیرن؛ اگر بخوام مثال بزنم میتونم اینجوری بگم که فرض کنید سیستم مورد نظر:
- بعد از 1000 ساعت کار کردن برای اولین بار با مشکل مواجه میشه و قطعی پیش میاد
- برای بار دوم و بعد از اینکه مجددا برای 1240 ساعت بدون مشکل کار کرده بوده به مشکل بر میخوره
- بار سوم زودتر از دفعات قبلی و بعد از 800 ساعت کار کردن به مشکل میخوره
- اما وقفه چهارم هم نسبت به تجربیات قبلی قابل قبول بوده و بعد از 1100 ساعت مشکل بوجود اومده
حالا اگر همین چهارتا عدد رو در نظر بگیریم و یک محاسبه خیلی ساده انجام بدیم میشه:
(1000+1240+800+1100) / 4 = 1035 = MTBF
و این عدد 1035 داره به ما نشون میده که تقریبا هر 1035 ساعت باید منتظر یک اتفاقی باشیم. یک پرانتز هم باز کنم که یک شاخص دیگه هم ممکنه بر بخورین به اسم MTTF (Mean Time To Failure) که برای تجهیزاتی استفاده میشه که امیدی به تعمیر و بازیابیشون نیست و یکجورایی لوازم مصرفی به حساب میان! مثل ماوس، کیبورد، باتری و …؛ این شاخص داره نشون میده که مثلا فلان ماوس 2000 ساعت کار میکنه و بعدش خب خراب میشه و باید بندازیمش دور 🙂
جمع بندی
همونطوری که توی بخشهای بالا مفصل توضیح دادم کاربرد هرکدوم از این شاخصها مهمه اما موضوع مهم این هست که ما آگاهانه بدونیم که برای چی داریم اینها رو پایش و اندازه گیری میکنیم و ارزش افزوده اینکار چیه! مثلا اینکه صرفا به این گیر بدیم که مقدار MTTR را باید کاهش بدیم موضوع لزوما مهمی نیست. چون ممکنه در شرایط سرویس ما و کاربری که ازش استفاده میکنه MTBF موضوع مهمتری باشه! پس نکته ای که باید روش خیلی دقت کنید این هست که هر کدوم از این شاخصها یک چیزی رو نشون میدن و کم و زیاد شدنشون به خودی خود خوب یا بد نیست و شما باید متناسب با نیاز مشتری و شرایط سرویس روی اینها تمرکز کنید. در نظر داشته باشید که اصل موضوع همون تمرکز روی مفاهیم “قابلیت اطمینان“، “تعمیرپذیری“، “دسترس پذیری” هستش و شما قراره به کمک این شاخصهایی که باهاشون آشنا شدین سعی کنید تا سرویس قابل اطمینانتر، در دسترستر و تعمیرپذیرتری را به مشتری ارائه کنید.
در آخر هم اگر بخوام یک نکتهای اضافه کنم، باید تاکید کنم که طبیعتا برای اینکه بتونید این شاخصها رو اندازهگیری کنید به این نیاز دارید که سوابق اصولی از حوادثی (Incident) که برای سرویسهاتون پیش میاد را ثبت و ذخیره کرده باشید تا بتونید روشون گزارش بگیرید و تحلیل کنید. پس برای اینکار قطعا به یک ابزار مناسب احتیاج دارید. اگر تمایل داشتید شرکت رایزن سامانه گستر به عنوان نماینده رسمی شرکت ماروال انگلستان در ایران میتونه یکی از بهترین و جامعترین ابزارهای حوزه ITSM/ITIL رو بهتون ارائه کنید. برای هماهنگی جلسه دمو و معرفی ابزار با شرکت در تماس (88508083-5) باشید.
** توضیح: عبارات MTRS و MTTRS در منابع مختلف با مفهوم یکسان مورد اشاره قرار گرفتهاند و فقط در یکی کاراکتر T از حرف اضافه TO نیز در عبارت مختصر شده لحاظ شده و در دیگری نه (Mean Time To Restore Service/System)!
ممکن است همچنین دوست داشته باشید


۱۰ تا از برترین ابزارهای CI/CD مورد استفاده برنامه نویسان
